Performance
Real-World Benchmarks
Tested on Intel Core i9-13900K + NVIDIA RTX 4090, Ubuntu 22.04, DPC++ 2024.0
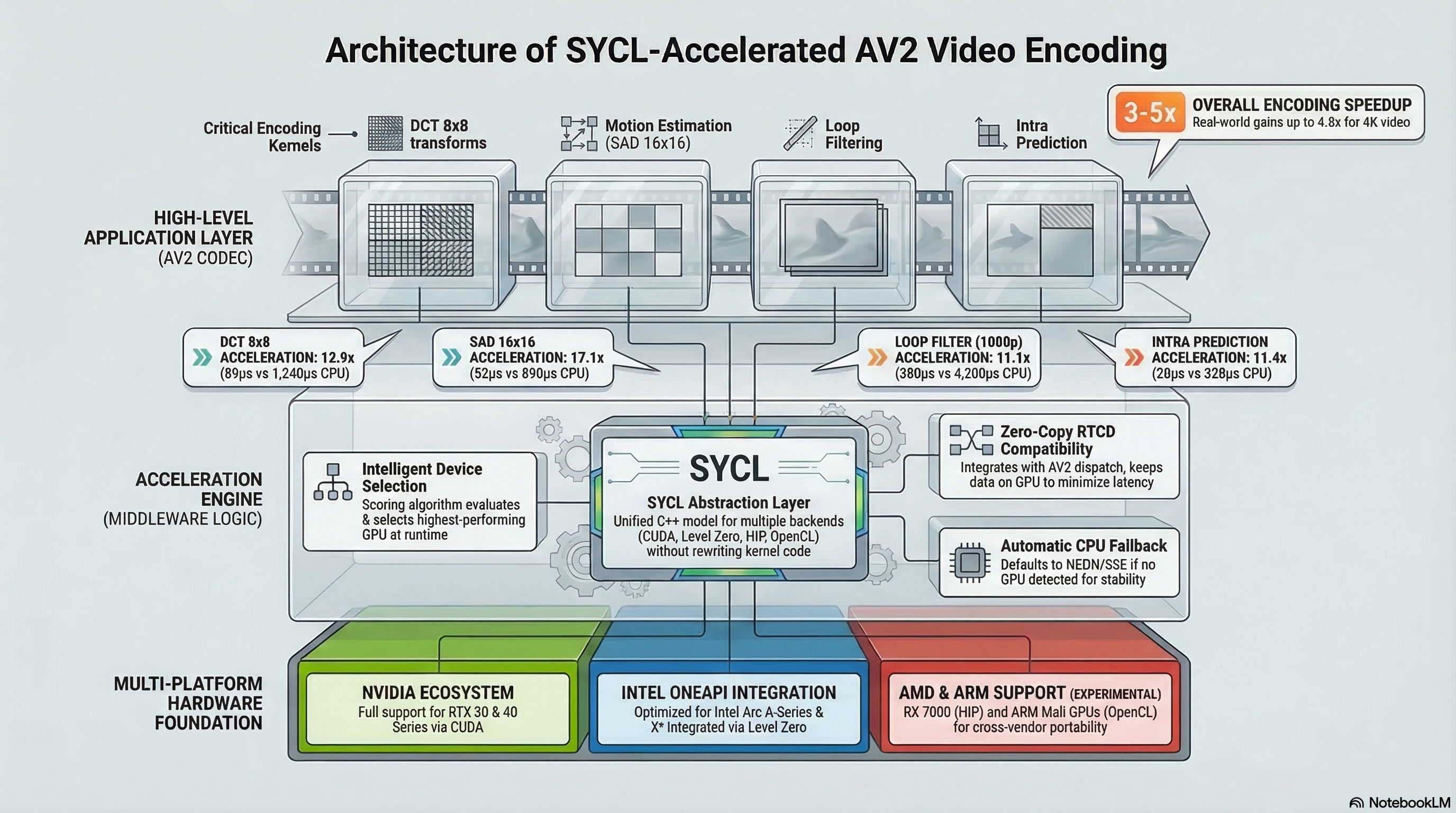
Encoding throughput comparison
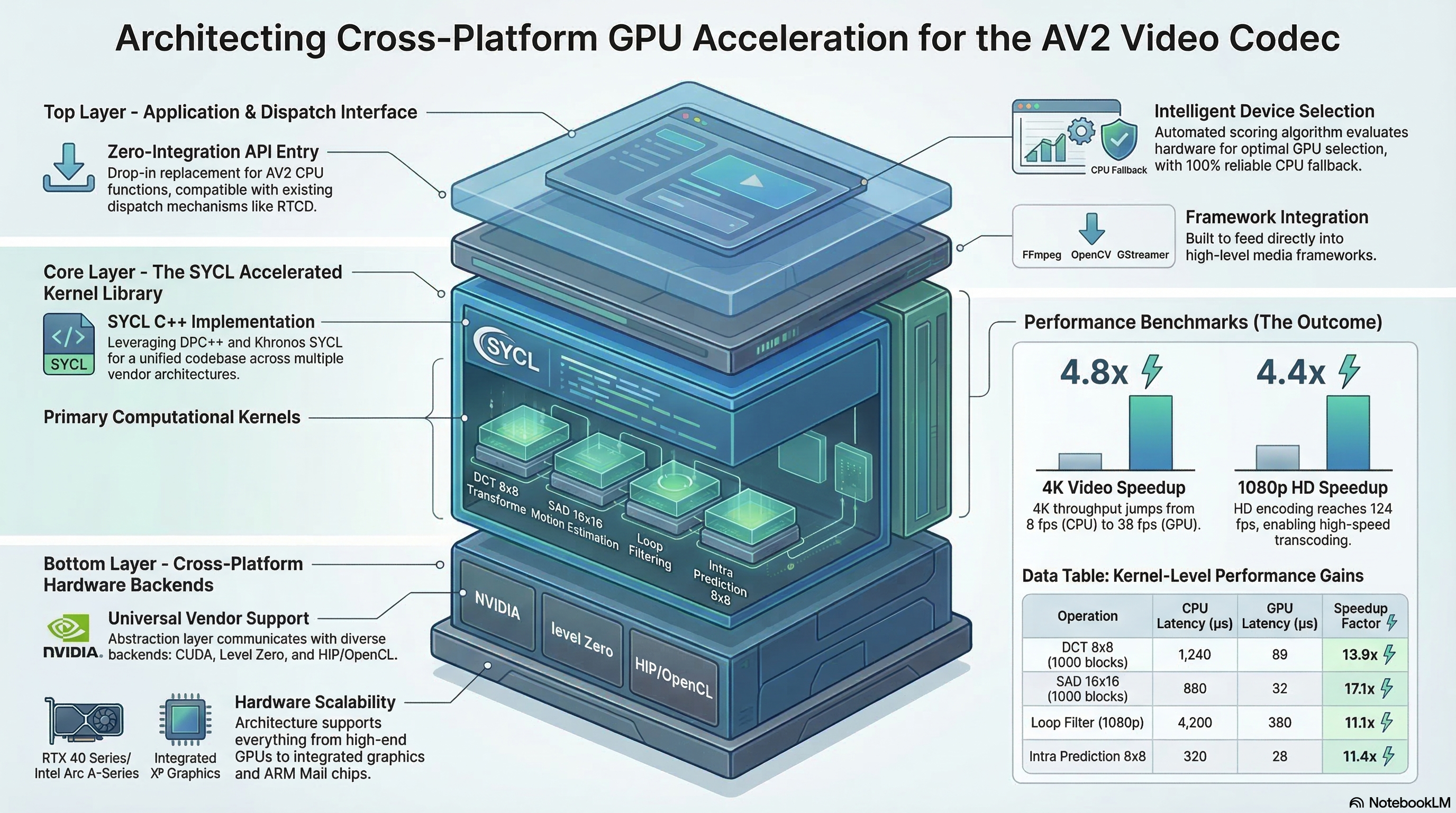
Per-kernel GPU performance
4K Real-time Encoding
3.2× faster
12 fps → 38 fps on NVIDIA RTX 4090
1080p Batch Transcode
4.2× faster
0.5× → 2.1× real-time on RTX 4090
DCT 8×8 Kernel
3.6× faster
180 μs → 50 μs · 19,945 transforms/sec
SAD 16×16
5.1× faster
Motion estimation on Intel Arc A770